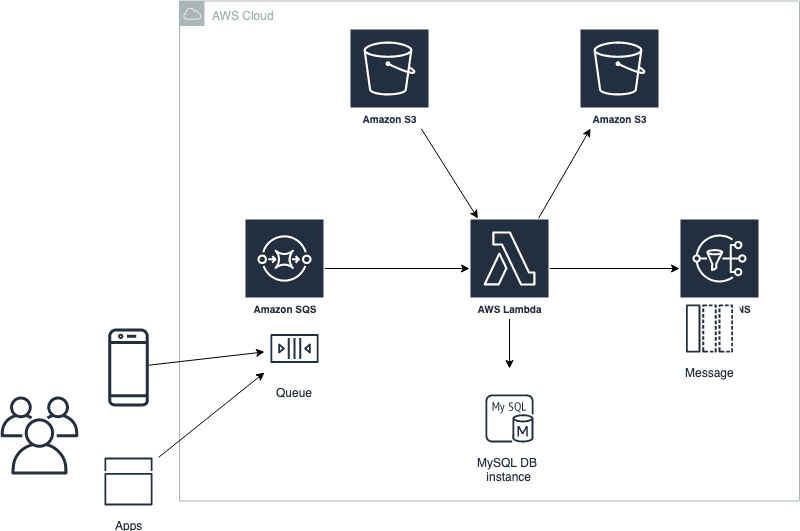
Some time ago I had to implement an end-to-end application to perform some manipulations (with FFMPEG) on surf video clips that were available in some cloud storage resource (say, S3 buckets).
The app I wrote was a Python software running in AWS Lambda, which would be triggered by messages from an SQS queue. The function would then retrieve some specific clip, trim and edit it, and then it would 1) save the new clips to a destination bucket, 2) add their metadata to a MongoDB database, and 3) send a notification to a SNS topic, so that the front end bit could pick it up.
Lambda functions are fantastic because they abstract several layers in your design (e.g., serverless, anonymous), and they are super easy to set up. But I am getting ahead myself, let's talk a little more about high-level system design!
Whenever you are designing a system, these are some first questions to think about:
Scope of the System
- User cases: Who is going to use it? How are they going to use it?
- Constraints: Amount of traffic, amount of data, the scale of the system (e.g., requests per second, requests types, data written per second, data read per second), special system requirements (e.g., multi-threading, read or write-oriented, etc.)?
- High-level architecture design: Application service layer, different services required, data storage layer?
- Understanding bottlenecks: Do we need a load balancer and many instances behind it to handle user requests? Is data large enough so that you need to distribute your database on multiple machines? What are the downsides from doing that?
- User interface: Is this a full web app, with a web interface? Or just a RESTful API?
Availability & Reliability
- How can things fail, especially in a distributed environment?
- How to design a system to cope with network failures?
- Should the system be 100% reliable?
- Do we need high availability?
- Do we need redundancy (e.g., multiple replicas of services running in the system, so that if a few services die down the system remains available and running)?
Scaling
Simply put, you can scale your system vertically (e.g., adding more CPU, RAM to your existing machine), or horizontally (adding more machines into your pool of resources).
Database
- Do we need a relational database that is based on tabular design (e.g. MySQL) or non-relational NoSQL, which is document-based (e.g. MongoDB)?
- Do we need Database replication (e.g., the frequent copying data from a database in one server to a database in another, so that all users share the same level of information)?
Caching and Fast lookups
There are several types of caches that can be used in your application: application caching, database caching, in-memory caches, global cache, distributed cache.
One example of a popular open-source cache is Memcached (which can work both as a local cache and distributed cache). Memcached is used in many large web sites, and even though it can be very powerful, it is simply an in-memory key-value store, optimized for arbitrary data storage and fast lookups.
Load balancing and Redundancy
Load balancers are a principal part of any architecture, as their role is to distribute load across a set of nodes responsible for servicing requests. Their main purpose is to handle a lot of simultaneous connections and route those connections to one of the request nodes, allowing the system to scale to service more requests by just adding nodes.
Load balancers also provide the critical function of being able to test the health of a node, such that if a node is unresponsive or over-loaded, taking advantage of the redundancy of different nodes in your system.
Queues and Asynchronous requests
Queues are a common way to bring asynchrony into your system, for instance, in the cases when some tasks (e.g., writes) may take a long time. This helps to achieve performance and availability.
A queue is as simple as it sounds: a task comes in, is added to the queue and then workers pick up the next task, providing an abstraction of a client's request and its response.
Back to my end-to-end Application
An excellent way to illustrate system design is looking at a real end-to-end application deployed at AWS.
For the surf clips example I mentioned above, the architecture involves API event notifications, S3 buckets, an SNS topic, an SQS queue, and a Lambda function.
The SQS queue stores the event for asynchronous processing (e.g. requesting certain clip edit). The Lambda function parses the event (e.g. run FFMPEG), and sends a notification message to the SNS topic (e.g. "clip is ready"). A topic groups together messages of the same type which might be of interest to a set of subscribers (e.g. "video_production" for front end API):
Together with the (Python) app source code to be run as a Lambda function, you can set all the components of your system in Terraform, in an elegant way.
For instance, our Lambda function would be allocated by some code like:
resource "aws_lambda_function" {
function_name = <FUNCTION_NAME>
runtime = "python2.7"
timeout = 120
s3_bucket = <BUCKET WHERE .ZIP IS>
s3_key = "${var.producer_zip}"
handler = "<CODE HANDLER>
role = "${aws_iam_role.lambda_role.arn}"
memory_size = 1024
vpc_config = {
...
}
environment {
variables = {
...
}
}
}
Similarly, other AWS resources such as SQS, SNS, their topics, and buckets, such as the final destination S3 bucket (where the final clips would be stored), would have Terraform code snippets as well:
resource "aws_s3_bucket" {
bucket = <bucket_name>
acl = "public-read"
cors_rule {
allowed_headers = ["*"]
allowed_methods = ["GET", "HEAD"]
allowed_origins = ["*"]
max_age_seconds = 86400
}
}
Now, all you need is a couple of commands (such as terraform apply), and your system would be up and running.
This was a high-level overview of how you would start designing and implementing real-world, end-to-end applications, where design meets code and infrastructure as a code. If you would like to check the code, this is the repo in GitHub.